
Spatial reasoning from egocentric videos is inherently challenging because the observable evidence is constrained by the camera trajectory. Existing methods rely on single-turn inference, forcing models to resolve geometric ambiguity through semantic priors rather than verifiable evidence. We argue that spatial reasoning should be revisitable: conclusions formed under limited evidence should remain open to revision when complementary viewpoints become available. Building on this insight, we propose Reason, then Re-reason (ReRe), a training-free, inference-time framework with two phases. In the Reason Phase, an MLLM forms a spatial hypothesis from the original video. In the Re-reason Phase, it verifies or revises the hypothesis by observing a synthesized novel-view video. To enable effective cross-view revisiting, we design a Geometry-to-Video pipeline that renders strategically complementary novel views from predicted 3D geometry. Extensive evaluations on VSI-Bench and STI-Bench demonstrate that ReRe substantially boosts open-source MLLMs to rival proprietary state-of-the-art performance.
Motivation
Egocentric videos are trajectory-conditioned: the visual evidence is limited to what the recorded camera path happens to reveal, and the temporal order of frames rarely aligns with the scene's actual spatial topology. Compounding this, general-purpose MLLMs lack explicit 3D world modeling and only implicitly enforce cross-frame correspondence. So when a model must answer in one pass, it fills missing geometry with semantic priors and produces a plausible but wrong conclusion.
ReRe changes the interaction pattern. Instead of asking the MLLM to directly finalize an answer, it first surfaces a traceable spatial hypothesis and then explicitly checks that hypothesis against new cross-view evidence. This converts spatial reasoning from one-shot perception into hypothesis-driven verification.
Framework
Overview of the ReRe framework. Given an egocentric video and a spatial query, ReRe operates in two phases: the Reason Phase forms an initial hypothesis from the original view, and the Re-reason Phase verifies or revises it against a synthesized allocentric view. A Geometry-to-Video pipeline produces this complementary view from recovered 3D geometry via trajectory planning and view rendering.
The MLLM observes the original egocentric video, identifies objects and spatial cues, infers relations, and outputs a provisional answer with an explicit thinking trace.
The MLLM compares a synthesized allocentric video with its prior hypothesis, reflects on inconsistencies, and confirms or revises the final answer.
Geometry-to-Video
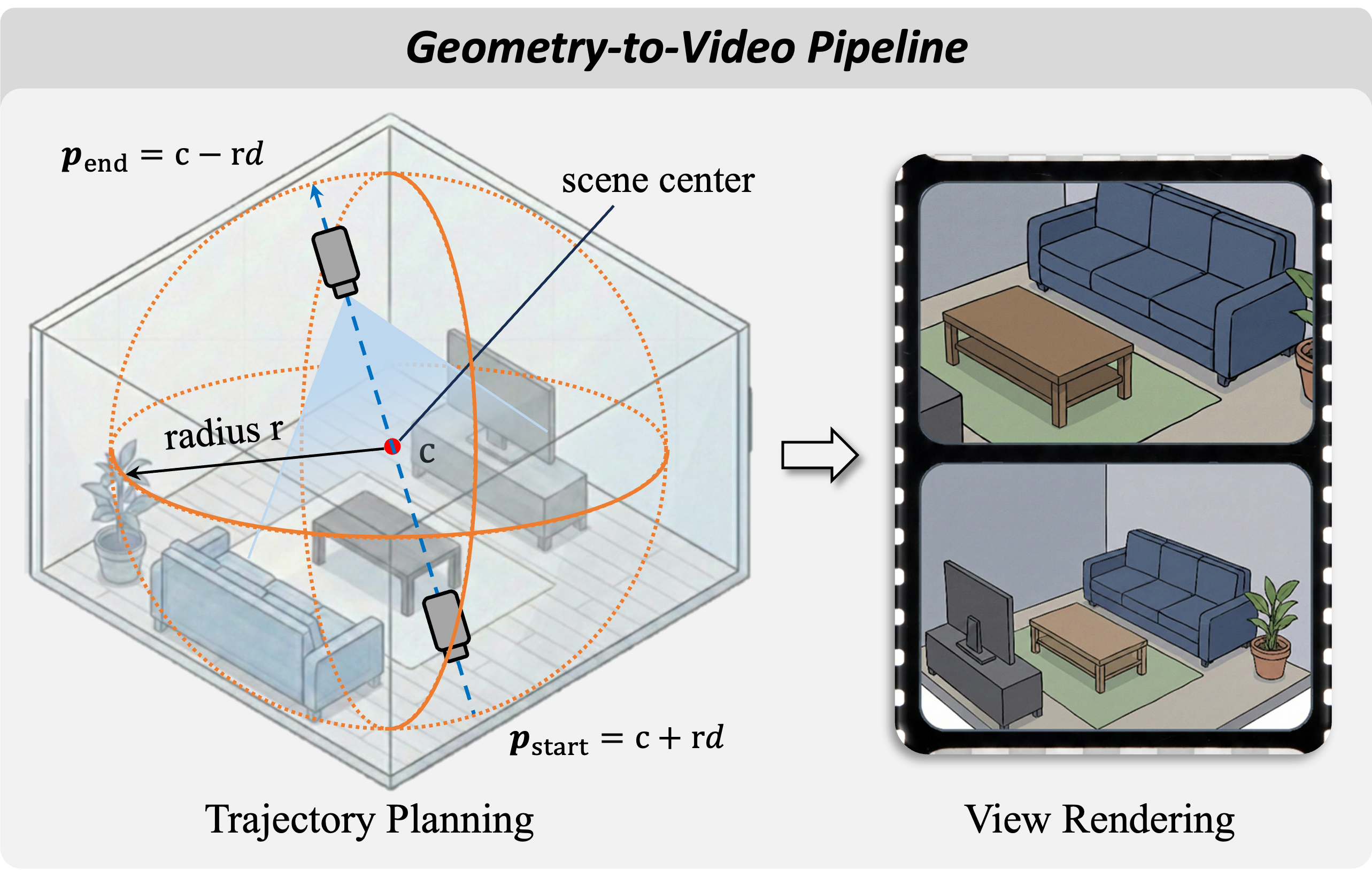
Geometry-to-Video pipeline. ReRe predicts a 3D point cloud from the egocentric video via VGGT, plans a scene-spanning Oblique Sweep trajectory, and renders the point cloud into temporally coherent video frames via point-based rasterization. This makes the geometric evidence natively consumable by frozen MLLMs without requiring architectural modifications or additional encoders.
The synthesized view is designed around two principles. Geometric complementarity requires a viewpoint that reduces inter-object occlusion and maximizes spatial coverage. Native compatibility means the geometric evidence must be presented in a familiar visual format rather than raw 3D representations like point clouds, so frozen MLLMs can consume it without architectural modifications.
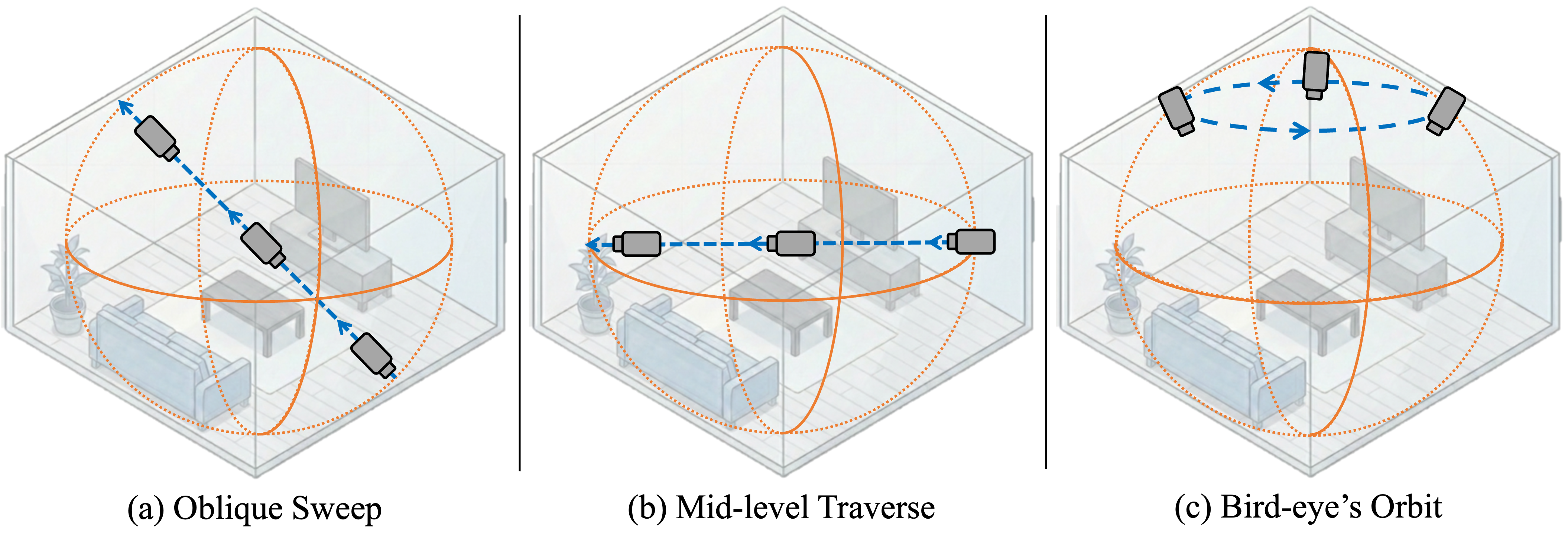
Allocentric trajectory design. The Oblique Sweep follows a diagonal path through the scene center with an elevated tilt. The Mid-level Traverse moves horizontally along the diameter at a fixed elevation, while the Bird's-eye Orbit circles the scene center from a top-down perspective.
Experiments
ReRe is evaluated zero-shot on VSI-Bench and the Static Understanding subset of STI-Bench, consistently improving frozen open-source models across the Qwen and InternVL families with no additional training. The largest gains appear in tasks that benefit from extra geometric evidence, such as object size, distance, relative direction, and spatial relation reasoning. For each benchmark we report the full subtask breakdown.
VSI-Bench Results
| Model | Avg. | Obj. Count | Abs. Dist. | Obj. Size | Room Size | Rel. Dist. | Rel. Dir. | Route Plan | Appr. Order |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | 34.0 | 46.2 | 5.3 | 43.8 | 38.2 | 37.0 | 41.3 | 31.5 | 28.5 |
| Qwen2.5-VL-3B | 26.4 | 15.8 | 23.9 | 33.4 | 27.8 | 20.5 | 34.4 | 29.9 | 21.5 |
| + ReRe | 28.2 +1.8 | 16.7 | 25.0 | 35.3 | 25.3 | 31.4 | 35.7 | 28.9 | 17.3 |
| Qwen2.5-VL-7B | 24.8 | 11.2 | 12.2 | 22.8 | 29.9 | 33.8 | 36.0 | 32.0 | 24.9 |
| + ReRe | 29.5 +4.7 | 18.0 | 18.8 | 40.0 | 31.1 | 34.1 | 35.3 | 32.5 | 22.0 |
| Qwen3-VL-2B | 22.5 | 14.2 | 14.7 | 29.8 | 10.8 | 19.9 | 34.1 | 23.7 | 19.4 |
| + ReRe | 31.0 +8.5 | 17.4 | 23.4 | 50.5 | 21.0 | 25.8 | 36.7 | 27.8 | 26.2 |
| Qwen3-VL-4B | 30.7 | 14.8 | 22.0 | 41.6 | 33.5 | 30.1 | 38.4 | 23.7 | 29.5 |
| + ReRe | 36.5 +5.8 | 21.1 | 26.7 | 50.2 | 35.8 | 37.2 | 43.1 | 28.9 | 34.1 |
| Qwen3-VL-8B | 30.5 | 16.4 | 20.7 | 43.0 | 28.0 | 36.8 | 35.1 | 22.7 | 26.9 |
| + ReRe | 35.8 +5.2 | 19.5 | 25.8 | 49.8 | 31.3 | 39.7 | 41.0 | 29.4 | 33.8 |
| InternVL2.5-4B | 31.3 | 37.6 | 24.5 | 37.4 | 22.7 | 32.0 | 33.2 | 27.8 | 26.9 |
| + ReRe | 32.3 +1.0 | 35.8 | 23.3 | 36.9 | 23.7 | 32.5 | 42.1 | 30.9 | 22.8 |
| InternVL2.5-8B | 35.5 | 22.5 | 28.4 | 45.6 | 35.3 | 35.6 | 43.3 | 32.5 | 29.9 |
| + ReRe | 36.7 +1.2 | 19.1 | 29.7 | 46.7 | 37.9 | 36.5 | 46.9 | 31.4 | 32.0 |
| InternVL3-2B | 26.5 | 42.2 | 22.8 | 26.4 | 17.6 | 25.2 | 34.3 | 25.8 | 10.8 |
| + ReRe | 29.9 +3.4 | 37.9 | 24.3 | 27.2 | 16.6 | 32.0 | 43.2 | 26.8 | 18.3 |
| InternVL3-8B | 32.6 | 40.4 | 23.3 | 43.4 | 30.1 | 34.9 | 33.4 | 30.9 | 19.3 |
| + ReRe | 35.5 +2.9 | 38.8 | 31.1 | 44.4 | 30.0 | 37.2 | 37.3 | 30.9 | 23.6 |
STI-Bench (Static Subset) Results
| Model | Avg. | Dim. Meas. | Spatial Rel. | 3D Video Grounding |
|---|---|---|---|---|
| GPT-4o | 31.0 | 24.9 | 49.6 | 28.1 |
| Gemini-2.0-Flash | 36.9 | 33.7 | 50.0 | 33.7 |
| Gemini-2.5-Pro | 37.1 | 34.2 | 53.4 | 32.3 |
| Qwen3-VL-2B | 22.2 | 18.0 | 31.5 | 21.8 |
| + ReRe | 30.2 +8.0 | 24.6 | 50.0 | 26.2 |
| Qwen3-VL-4B | 29.7 | 29.8 | 41.8 | 24.3 |
| + ReRe | 34.4 +4.7 | 33.6 | 48.6 | 28.7 |
| Qwen3-VL-8B | 27.9 | 29.4 | 43.8 | 19.2 |
| + ReRe | 30.9 +3.0 | 29.1 | 44.5 | 26.2 |
| InternVL2.5-4B | 30.5 | 25.9 | 43.1 | 29.0 |
| + ReRe | 30.6 +0.1 | 22.2 | 43.2 | 32.5 |
| InternVL2.5-8B | 32.1 | 30.1 | 45.9 | 27.8 |
| + ReRe | 34.8 +2.7 | 33.2 | 49.3 | 29.7 |
| InternVL3-2B | 22.6 | 20.1 | 28.8 | 22.1 |
| + ReRe | 26.7 +4.1 | 22.5 | 43.8 | 22.7 |
| InternVL3-8B | 24.5 | 20.1 | 44.5 | 19.2 |
| + ReRe | 27.8 +3.3 | 28.0 | 37.0 | 23.3 |
Ablations
Qualitative Results

Qualitative results on VSI-Bench. ReRe resolves spatial ambiguities across four representative cases: (a)-(b) object counting, where synthesized novel views reveal previously unobserved objects such as a second monitor or a second bed; (c) absolute distance, where the expanded view clarifies the separation between the sofa and bed; and (d) relative direction, where the synthesized view disambiguates the window, door, and lamp configuration, correcting a right-side prediction to the correct left. In each case, the Re-reason Phase uses newly synthesized geometric evidence to revise an erroneous initial judgment.
Discussion
@inproceedings{ma2026reason,
title={Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning},
author={Ma, Chaofan and Mao, Zhenjie and Yang, Yuhuan and Zeng, Fanqin and Shi, Yue and Zhou, Yingjie and Cao, Xiaofeng and Yao, Jiangchao},
booktitle={International Conference on Machine Learning},
year={2026}
}